
嫁からインフルエンザが感染しないまま、嫁は完治のほうに進んできていて、明日には完全復活ののろしが上げられるところにきています。お陰様で、娘へも私へも感染することなく、めでたく時が過ぎていっています。が、ここに来て、昨日から咳がひどくなってきたりしているのは、何の因果でしょうか。 [I]熱は今朝もいつもどおりの35.5度
さて、複数拠点でのファイルの共有や、被災時のファイルのバックアップとして、みなさまは何をお使いでしょうか。
私は dropbox の無料版でファイルの共有を、Evernote有償版でデータの共有をしています。極力コストを抑えるために、ファイル共有サービス系は有償のものを利用していないんですね。
とは言え、被災を考慮した場合に、ファイル共有だけを目的としないファイルの保護は必要です。ものとして残らないだけに、データを安価に、大容量のデータを保管できる方法はなにか、考える必要が出てきました。
そこで行き着いたのが”Amazon S3 (クラウドストレージサービス Amazon Simple Storage Service) | アマゾン ウェブ サービス(AWS 日本語)“です。保管した容量と Read/Write回数による月額従量制サービスです。
数百GBのサイズになると、dropboxなどのストレージ共有サービスでは月額数千円にもなります。よくよく考えれば、ストレージ共有サービスのbackendは Amazon S3だったりするので、素直にS3にしておくのが良いのではないか、ということで、S3を利用することになりました。
しかし、容量が大きくなってくると、それなりに月額料金がかさんでくるので、さらにコストを抑制する方法がないか、検討しました。
そこで、最近使い始めたものが”Amazon Glacier (低価格アーカイブストレージサービス) | アマゾン ウェブ サービス(AWS 日本語)“です。単純に比較はできませんが、およそ S3の 1/10程度の金額、月額$0.01/GBでファイルを保管することができます。1TB保管してやっと千円近くですね。ただし、一度保管したデータを取得するには、時間がかかりますので、主に保管を目的としたサービスと言うことになります。
S3とGlacierのILMを組んで低コスト化する
これまで S3にファイルをバックアップしていただけの人は、S3 のファイルを Glacierへ移管するだけで、月額のコストが一桁落ちることでしょう。
しかし、私のように、ファイル共有と保管、両方を利用している場合、S3との同期をメインに利用しているため、S3 とのインタフェイスが欠かせません。S3を使いつつも、Glacierサービスを利用する方法はなのでしょうか?
あります
“Amazon S3から自動的に安価なAmazon Glacierへアーカイブする新機能が登場 - Publickey“にもありますように、S3 の “Lifecycle”機能を使います。
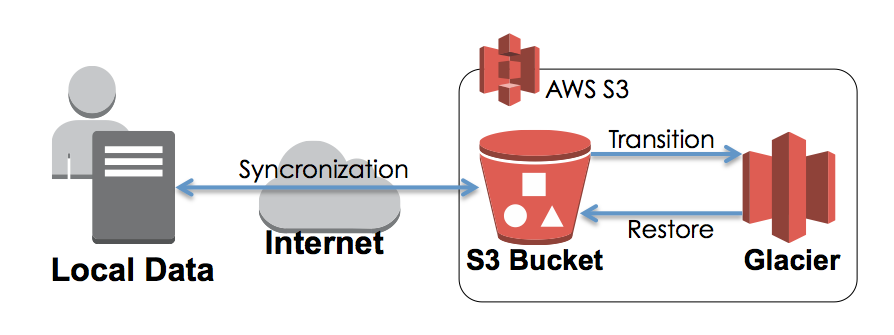
概念的には下図のようになります。
localのデータと、S3で基本的にはデータの同期をしています。そのうち、更新の発生しない、保管用のデータは Glacierへ自動的にアーカイブされます。AWSでは、これを “Transition” とも呼んでいますね。基本的には Glacierへ入ったデータは、そこで塩漬けです。問題が発生しないうちはここからの抽出はありません。
もし、不測の事態が発生し、Glacier からデータが必要となった場合は、一度、GlacierからS3へ “Restore” が発生します。この時、復帰には3〜5時間程度の時間がかかると明示されています。Restore完了後、S3からデータを読み出すことができるようになるという仕組みです。
では、実際に設定してみましょう。
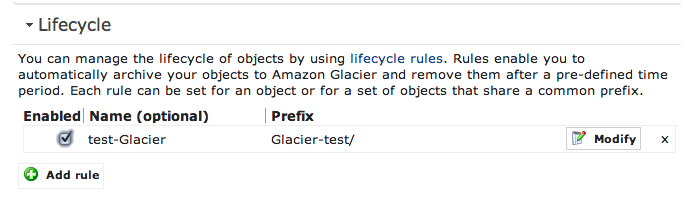
S3で利用していたデータを、「登録から何日以上経過したらGlacierへアーカイブする」という設定が可能です。
このように、データの使用頻度などによって、階層化し、保管されるべきストレージ/保管先を制御することを”情報ライフサイクル管理 – Wikipedia“、略して「ILM」と呼んだりしています。ILMの全てがこのアーカイブ昨日のことではありませんが、その一部ということですね。
それでは、新たに作る場合は[Add]を、既存のものを変更するには、その定義の[Modify]をすると、Lifecycle の設定画面に移ります。
S3 Lifecycleの設定
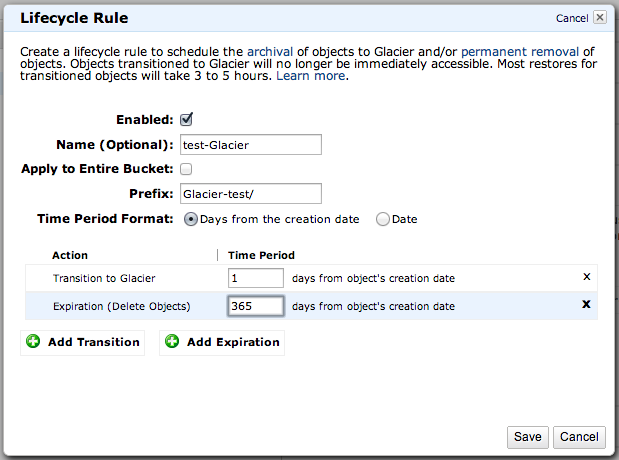
- Enabled
- ここをチェックすると、ココで設定したルールが実行されます
- Name(Optional)
- 識別するための名前です。好きなものを入れればいいと思います
- Apply to Entire Bucket
- こちらをチェックすると、指定したBucket全てのファイルに、このLifecycleのルールが適用されます。
- Prefix
- 対象となるファイルのPrefixを指定します。対象となるディレクトリを入れると良いと思います。ファイル単位はちょっと…
- Time Period Format
- ファイルの作成日からの経過日数か、指定した日付、のいずれかをもって対象となるファイルをアーカイブするかを指定できます。
- Add Transition → Transition to Glacier
 「Time Period Format」で指定したように日数か日付を入力します。対象のファイルが、ここで指定した日にGlacierへアーカイブされます。
「Time Period Format」で指定したように日数か日付を入力します。対象のファイルが、ここで指定した日にGlacierへアーカイブされます。
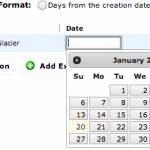
「Date」を指定した場合は右の写真のようにカレンダーから選択できますね。
S3へファイルを保管したら、すぐにアーカイブしても良いような保管・保護が目的のデータであれば、ここの日数指定を短くし、ファイル共有にも利用するようなファイルが保管されている場所であれば、日数を3ヶ月など、ご自分のファイルとの利用目的に合わせて調整することが可能です。
S3に保管したデータを、再度利用することがあるかないか、だいたいどの程度の期間内に見直すケースがあるかを含めて余裕を持って設定すると良いでしょう。私の場合、保管が目的の家族の写真などは’1’日で設定しています
- Add Expiration → Expiration (Delete Objects)
- これは Glacierへアーカイブしたデータをいつ削除するか、と言う指定になります。特に削除が必要なく、半永久的に保存が必要なものであれば、指定の必要はありません。
監査などのデータで、指定した期日が到達し、不要になるデータなどは、こちらで指定して自動的に削除することが可能です。いくら安いとは言っても、溜まればそれなりのコストになりますからね。入らなくなるものは削除して構わないと思われます。
今回の設定では、”Glacier-test/” ディレクトリ内のファイル全てを、S3へファイルが登録されてから “1日後” にGlacierへアーカイブします。
そして、Glacierへアーカイブされたデータは “1年(365日)”経過したら、Glacierからも削除される、ということになります。
なお、Glacierへアーカイブされたデータは、S3からは削除され、Glacier に登録されますが、ファイル情報などの Metaデータは S3に残ったままとなりますので、S3 と同期するクライアントソフトを利用した場合でも、S3にあろうが、Glacierにあろうが、関係なく目的の同期処理は実行され、アーカイブされたデータをまた S3へアップロードするようなことはないようです。
コストの比較
コストについてですが、まったく同容量での比較は私の実績上ありませんが、コスト感覚は掴んでいただけると思います。
以下のように、使用量自体は30GBほど増加し、円安も 10円以上進んだ状況にも関わらず、全体の 67%程度にGlacierを利用することで、半額以下になっています。Glacierアーカイブの割合が増えれば増えるほど、削減率も高くなりますし、個人ユースとしてはとてもコストパフォーマンスの良い、災害対策の一つになるのではないでしょうか。
2012/10のケース
99.24GB利用で、$9.23 = 770円(75円換算)

2012/12のケース
130.026GB利用で、$4.06 = 345円(85円換算)

[tmkm-amazon]B007Q4VYDK[/tmkm-amazon]
References
| ↑I | 熱は今朝もいつもどおりの35.5度 |
|---|
S3とGlacierを組み合わせて低価格遠隔地バックアップを実現する [Webストレージ]