
警告: 整合性のない脚注開始用の簡単コード:
この警告が見当違いであれば、管理画面の 全般設定 > 脚注の開始・終了用の簡単コード > 簡単コードの整合性を検査 にある構文検査の機能を無効にしてください。
整合性のない脚注開始用の簡単コード:
“”
皆様ご機嫌いかがでしょうか。「( ゚д゚)ハッ!この寒気はインフル…((((;゚Д゚))))ガクガクブルブル」を昨晩体験したものの、インフルではなかったしょっさんです、( ノ゚Д゚)こんばんわ。
 要するに調子悪いんです。今日のお仕事が、リモートでも観覧可能な社内カンファレンスでホント良かったです。半死半生、着の身着のままでカンファレンスに望んでいました。寝てれば良いのに、寝ずに全部聞いていたんですもの、社畜ですね。
要するに調子悪いんです。今日のお仕事が、リモートでも観覧可能な社内カンファレンスでホント良かったです。半死半生、着の身着のままでカンファレンスに望んでいました。寝てれば良いのに、寝ずに全部聞いていたんですもの、社畜ですね。
さて、この 1週間、DevOpsについて必死に考え込んでいるのですが「これだ」という結論(へ導く道程)がうまく定まらずに、自分の考えが浅はかだったのか、更に考え込んでいます。何もしてないわけじゃないんだけれども、そろそろ何か答えを出さないといけない。
どうしたものか…( ゚д゚)ハッ!
とこのネタを思い出しました。
“oshiire*BLOG» Blog Archive » [AWS] S3とGlacierを組み合わせて低価格遠隔地バックアップを実現する [Webストレージ]” と “oshiire*BLOG» Blog Archive » [ #qpstudy ] S3+Glacierで災対する件についてLTしてきた [2013.01]” の補足情報です ((そっちのかよ))
Glacierへアーカイブ済みの S3データを上書きしたらどうなるの?
お題の復唱です。必要です。
会話をしているときの相づちとして、復唱することや、要約をして聞き返すなどは、積極的傾聴スキルとして必須です。是非、覚えて帰ってください。

先日ご説明したように、S3 の Lifecycle機能を使うと、「ある一定の期日、指定した日数に達したデータを Glacierへアーカイブする」ことができます。実際に、S3上からはデータは無くなり、Glacierへ実体(Solid)はうつります。
この時、S3でも Metaデータは残っているので、最終更新日時やファイル名などの情報は持っており、その実体が Glacierへある、というポインタを示しています。
要するに、クライアントは S3とのインタフェイスだけを持っていて、そのファイルが Standard, RRS, はたまた Glacierのどこに保管されているか、は S3が自動的にうまいことやってくれているわけです。
ステキですね。そろそろ宣伝費が入るはずです。
では、このような状況の時に、S3へ同じファイルを同期(アップデート)するとどうなるのでしょうか。実体はGlacier にあるのですよ…?
S3に新しいファイルが入って、Glacierのアーカイブのことは忘れ去られる
ということで試してみました。
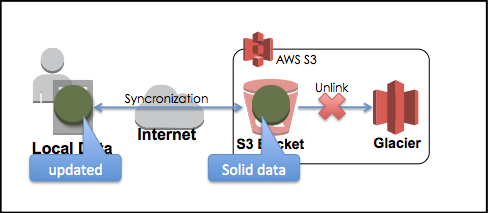
従って、Local と S3 との同期ソフトを使っている際に、Local側がいくら更新されていったとしても、その実体が S3でもGlacier でも、どちらに入っていても、問題なく同期処理を実行することができるというわけですね。
結局のところ、「Glacierに実体のあるデータを読み込む場合のみにおいて、3-5時間の読み込み待ち時間がかかる」わけであって、そのファイルの Metaデータは S3上に保管されているようですから、ファイルの実体を比較する場合でない限り、ファイルはどこにあっても良いと言うことでした。
基本的にS3側へバックアップだけの目的で配置する、共有目的のないデータについては、さっさと Glacierへ送ってしまうことが良さそうですね。
Glacier上のデータがどうなるかは、そのうち Amazonの人が教えてくれると、FAQに載っていると思います。この図はあくまでも、私の仮説です( ´ー`)y-~~
結論
「保管目的のデータは、Transition to Glacier を “0” または “1” に定義しやがれ」
珍しく結論を最後まで引っ張ってみました。日本語っぽいでしょ。
[tmkm-amazon]B003F256OA[/tmkm-amazon]